层次聚类(hierarchical clustering)
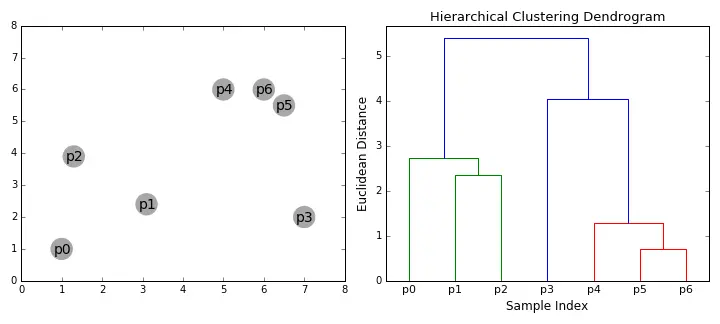
如图所示为层次聚类的基本算法流程:
初始化每个样本独自一个聚类。选取相似度最高的聚类合并,重复操作直到最小聚类数或相似度小于某阈值。
层次聚类类似于构建树的过程,因此在数据结构上可优先选取二叉树结构。
聚类相似度
各种距离计算不再赘述,而基于距离描述的相似度有以下几种方式:
- Single Linkage即取两聚类最近邻样本聚类作为两聚类的距离,受极端值影响较大,可能两聚类因为偶然离得比较近的两个点而被合并,导致最终得到的大聚类中的点分布较为松散
- Complete Linkage即取两聚类相距最远样本作为两聚类距离,与single linkage完全相反
- Average Linkage即取两聚类之间两两样本平均距离,平均值计算总是被诟病受极端值影响较大,因此实际可采用中位数估计一定程度抵消该种弊病。
代码实现
1 | 见github主页 |