One-class classification
Estimating the Support of a High-Dimensional Distribution
1、Generally, they can be characterized as estimating functions of the data, which reveal something interesting about the underlying distributions. For instance, kernel principal component analysis (PCA) can be characterized as computing functions that on the training data produce unit variance outputs while having minimum norm in feature space (Sch¨olkopf, Smola, & M ¨uller, 1999). Another kernel-based unsupervised learning technique, regularized principal manifolds (Smola, Mika, Sch¨olkopf, & Williamson, in press), com-putes functions that give a mapping onto a lower-dimensional manifold minimizing a regularized quantization error. Clustering algorithms are fur-ther examples of unsupervised learning techniques that can be kernelized (Sch¨olkopf, Smola, & M ¨uller, 1999).
核方法可被特征化为数据的估计函数,其揭示了数据潜在的分布。例如,给予核的PCA方法可被特征化为计算函数,该函数在训练集上产出特征空间中最小范数的单位方差输出。另一种基于核的无监督学习方法,regularized principal manifolds,这种计算函数通过最小化正则量化误差给出了原始数据到低维manifold的映射。聚类也是一种可被核化的无监督学习方法。
2、Section2 Previous Work
挖坑(知识有限,不能理解)
3、OCSVM
挖坑,SMO优化及改进
xgbt
GBDT梯度提升决策树
集成学习(Ensemble Learning)
集成学习是指构建合并多个学习器完成学习任务,又分为同质集成和异质集成。顾名思义,同质集成是指包含不同种类型的个体学习器,而异质集成则指代包含非同种的个体学习器。同质集成中的个体学习器亦称基学习器,而异质集成中的个体学习器亦称组件学习器。
我们所能听到的另一个词语,弱学习器,实际上是指我们上面提到的个体学习器。
目前集成学习方法可大致分为两类,一类是指个体学习器存在强相互依赖关系,串行化序列生成,另一类指同时生成的并行化方法,这两类分别是我们常说的Boosting和Bagging。
GBDT
XGBoost
代码实现
1 | 见github主页 |
hierarchical
层次聚类(hierarchical clustering)
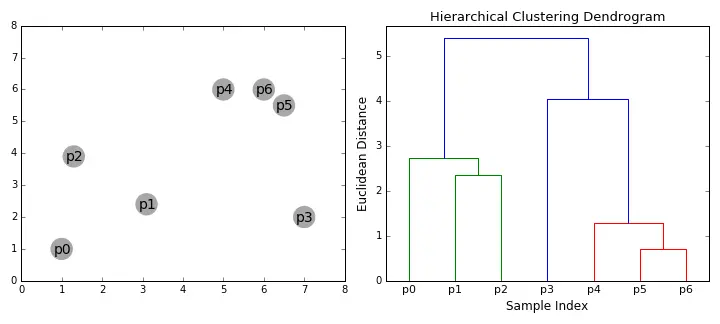
如图所示为层次聚类的基本算法流程:
初始化每个样本独自一个聚类。选取相似度最高的聚类合并,重复操作直到最小聚类数或相似度小于某阈值。
层次聚类类似于构建树的过程,因此在数据结构上可优先选取二叉树结构。
聚类相似度
各种距离计算不再赘述,而基于距离描述的相似度有以下几种方式:
- Single Linkage即取两聚类最近邻样本聚类作为两聚类的距离,受极端值影响较大,可能两聚类因为偶然离得比较近的两个点而被合并,导致最终得到的大聚类中的点分布较为松散
- Complete Linkage即取两聚类相距最远样本作为两聚类距离,与single linkage完全相反
- Average Linkage即取两聚类之间两两样本平均距离,平均值计算总是被诟病受极端值影响较大,因此实际可采用中位数估计一定程度抵消该种弊病。
代码实现
1 | 见github主页 |
fcmeans
模糊C均值聚类(Fuzzy c-mean clustering)
模糊是指没有明确边界划分无法精确刻画的现象称为模糊。
对离散且有限的论域
其模糊集可表示为
其中 $F$ 称为隶属度函数
介绍及引入
我们所谓的kmeans聚类,也就是c均值聚类,可以称之为硬C均值聚类。
给定样本集 $D = {x{1},x{2},…,x{m}}$ ,k均值聚类算法针对聚类所得簇划分 $C = {C{1},C{2},…,C{k}}$ 最小化平方误差
其中
模糊概念的引入使得该聚类叫做软C均值聚类,允许每个样本属于一个或以上更多的聚类。可以设想,对于某个样本点,可构建到每个聚类的隶属度函数,设样本数为 $n$ ,聚类数为 $C$ ,则存在 $n*C$ 的隶属度矩阵,每个样本与聚类的硬距离乘对该聚类的隶属度总体求和保证最小,便是模糊C均值聚类所解决的问题。
原理
Fuzzy C-Means聚类所优化的目标函数如下:
$m$ 为大于1的任意实数。(至于 $m$ 具体作用也没有深入考虑 $TODO…$
针对上述目标函数优化,采用启发式迭代。
迭代停止条件可取隶属度矩阵变化值小于某 $\xi$ 时停止。
代码实现
1 | 见github主页 |
ubuntu tips
创建应用程序快捷方式
快捷方式存放位置 /usr/share/applications/
sudo touch /usr/share/applications/empty.desktop
# empty 代指 应用程序名称
sudo vim /usr/share/applcations/empty.desktop
1 | [Desktop Entry] |
tensorflow tips
tf.InteractiveSession() 与 tf.Session()
1 | sess = tf.InteractiveSession() |
而tf.Session()前必须构建好图,再创建session1
2
3
4
5
6
7
8# Build a graph
a = tf.constant(5.0)
b = tf.constant(6.0)
c = a * b
# Launch the graph in a Session
sess = tf.Session()
# Evaluate the tensor 'c'
print(sess.run(c))
tf.app.flags 与 python3 absl.flags
1 | from absl import app |
1 | import tensorflow as tf |
1 | import argparse |
tf.train.ExponentialMovingAverage
Some training algorithms, such as GradientDescent and Momentum often benefit from maintaining a moving average of variables during optimization. Using the moving averages for evaluations often improve results significantly.
tf.train.ExponentialMovingAverage.__init__(self, decay, num_updates=None, zero_debias=False, name="ExponentialMovingAverage"):
参数的移动平均验证效果优于最终训练的结果。
$shadow_variable$ 最初为参数的 $copy$ ,上次为指数衰减, $decay$ 为衰减速率,一般为 $0.9, 0.99$ 等接近 $1$ 的数。
一般来讲,decay越大模型越稳定,因为参数更新更慢,趋于稳定。
1 | import tensorflow as tf |
可参考吴恩达 $deeeplearning.ai$ 指数加权平均。
tf.add_to_collection 与 tf.get_collection
1 | import tensorflow as tf; |
例如在使用L2正则化,网路各层变量需计算tf.nn.l2_loss,将其加入loss列表,最后创建操作求和。
tf.control_dependencies
1 | with g.control_dependencies([a, b, c]): |
tf.name_scope 与 tf.variable_scope
总结
1.tf.variable_scope 与 tf.get_variable 必须搭配使(全局 scope 除外)
2.tf.Variable 可以单独使用,也可以搭配 tf.name_scope 使用,给变量分类命名,模块化
3.tf.Variable 与 tf.variable_scope 搭配使用不伦不类,不是设计者的初衷
当前环境作用域可通过 tf.get_variable_scope 获取。
tensorflow.contrib.slim API
1 | import tensorflow as tf |
1 | # slim convolution 原型 |
1 | import tensorflow as tf |
slim简化更有利于复杂网络编程,slim更多内容请参考官方说明
kmeans clustering
k-均值聚类(k-means clustering)
聚类试图将数据集中的样本划分为若干个通常是不相交的子集。

距离计算 $dist(\cdot,\cdot)$
对函数 $dist(\cdot,\cdot)$,若它是一个距离度量,则需满足:
非负性: $dist(x{i},x{j}) \geq 0$
同一性: $dist(x{i},x{j}) = 0$ 当且仅当 $x{i} = x{j}$
对称性: $dist(x{i},x{j}) = dist(x{j},x{i})$
直递性: $dist(x{i},x{j}) \leq dist(x{i},x{k}) + dist(x{k},x{j})$
给定样本 $x{i} = (x{i1},x{i2},…,x{in})$ 与 $x{j} = (x{j1},x{j2},…,x{jn})$ ,最常用的是“闵可夫斯基距离”(Minkowshki distance)
当 $p=2$ 即欧式距离(Euclidean distance)。
当 $p=1$ 即曼哈顿距离(Manhattan distance)。
上式仅适用于有序属性(ordinal attribute),针对属性定义域{飞机,轮船,火车}等则属于无序属性(non-ordinal attribute)。
对于无序属性可采用VDM(Value Difference Metric),令 $m{u,a}$ 表示在属性 $u$ 上取值为 $a$ 的样本数, $m{u,a,i}$ 表示在第 $i$ 个样本簇中在属性 $u$ 上的取值为 $a$ 的样本数, $k$ 为样本簇数,则属性 $u$ 上两个离散值 $a$ 与 $b$ 之间的VDM距离为
假设混合属性有 $n{c}$ 个有序属性、 $n-n{c}$ 个无序属性,则
当样本中属性重要性不同时,可使用“加权距离”(weighted distance)。
通常 $\sum{i=1}^{n}w{i}=1$ 。
算法流程
给定样本集 $D = {x{1},x{2},…,x{m}}$ ,k均值聚类算法针对聚类所得簇划分 $C = {C{1},C{2},…,C{k}}$ 最小化平方误差
其中
直接求解该式为NP hard问题,因此采用启发式迭代。
缺点
- 不能保证定位到聚类中心的最佳方案,但能保证收敛到某个具体方案,即局部最优点
- 算法无法指出类别数,在同一数据集中,选择不同类别得到的结果不同,甚至不合理
改进
- 多次聚类,初始化聚类中心不同,选择方差最小的结果
- 将类别设置为1,逐步提高类别数,一般情况下,总方差快速下降直到达到某个拐点,这意味着再加一个新的聚类中心也不会显著减少总体方差。
TODO…
1 | python实现 |
参考资料
机器学习西瓜书